|
目的: 正文目录: 1. Linux 的两大抽象2. 文件类型3. 文件描述符4. 通用文件模型:简介 4.1 演示 demo 4.2 相关要点: 与 VFS 的关系5. 通用文件模型:文件描述符和打开文件的关系 5.1 相关的内核数据结构 5.2 列举几种打开文件的情景
1. Linux 的两大抽象- 文件是 Linux 系统中最基础最重要的抽象。Linux 遵循一切皆文件的理念。很多交互操作是通过读写文件来完成,即使所涉及的对象看起来并非普通文件。
- 另外一大抽象是进程。如果说文件是 Linux 系统最重要的抽象概念,进程则仅次于文件。
- 进程相关的实现复杂且多变,而文件 IO 的实现则相对稳定很多,且更贴近我们的日常操作,所以 以文件作为学习 Linux 内核的切入点是个更好的选择。
2. 文件类型Linux 系统的大多数文件是普通文件或目录,但是也有另外一些文件类型,具体包括如下几种: - 普通文件 ( regular file )。
- 最常用的文件类型,包含了某种形式的数据。至于这种数据是文本还是二进制数据,对于 Linux 内核而言并无区别。
- 文件中包含的字节可以是任意值,可以以任意方式进行组织。在系统层,除了字节流,Linux 对文件结构没有特定要求。
- 对普通文件内容的解释由处理该文件的应用程序进行。
- 文件虽然是通过文件名访问,但文件本身其实并没有直接和文件名关联。相反地,与文件关联的是索引节点 (inode,是index node 缩写)。针对驻留于文件系统上的每个文件,文件系统都会为其分配一个 inode。inode 中会保存和文件相关的元数据,如文件修改时间戳、所有者、类型、长度以及文件数据的位置,但不含文件名,文件名由目录文件负责。
- inode 由 inode number 来标识,可以通过 “ls –li” 查看文件的 inode number。
# ls -li minicom.log
12582945 -rw-r--r-- 1 root root 665 Jul 10 18:47 minicom.log
- 目录文件 ( directory file )。
- 目录也是一种文件类型,这种文件包含了其他文件的文件名以及 inode number。文件通常是通过文件名从用户空间打开,目录用于提供访问文件时需要的名称。
- 文件名和 inode 之间的配对称为链接 (link)。映射在物理磁盘上的形式,如简单的表或散列,是通过特定文件系统的内核代码来实现和管理的。
- 如果用户空间的应用请求打开指定文件,内核会打开包含该文件名的目录,然后根据文件名获取 inode number。通过 inode number 可以找到 inode。inode 包含和文件关联的元数据,其中包括文件数据在磁盘上的存储位置。
- 硬链接 ( hard link )。
- 不同的文件名可以链接到到同一个 inode。当不同名称的多个链接映射到同一个索引节点时,我们称该链接为硬链接。
- 硬链接通常要求链接和文件位于同一文件系统中。
- 在底层文件系统支持的前提下,也只有超级用户才能创建指向目录的硬链接。
- 符号链接 ( symbolic link )。
- 符号链接是对一个文件的间接指针,它与硬链接有所不同,硬链接直接指向文件的 inode。引入符号链接的原因是为了避开硬链接的一些限制。
- 硬链接不能跨越多个文件系统,因为 inode number在自己的文件系统之外没有任何意义。为了跨越文件系统建立链接,Linux 系统实现了符号链接。
- 特殊文件 (special file)。
- 特殊文件是使得某些抽象可以适用于文件系统,贯彻一切皆文件的理念。
- Linux 只支持四种特殊文件:块设备文件、字符设备文件、命名管道 以及 UNIX域套接字。
- 块特殊文件 ( block device file )。提供对设备(如磁盘)带缓冲的访问,每次访问以固定长度为单位进行。
- 字符特殊文件 ( character device file )。这种类型的文件提供对设备不带缓冲的访问,每次访问长度可变。系统中的所有设备要么是字符特殊文件,要么是块特殊文件。
- 命名管道 ( named pipes ),通常称为 FIFO,是以文件描述符作为通信信道的 IPC 机制,它可以通过特殊文件来访问。
- 套接字 ( socket ) 是最后一种特殊文件。socket 是进程间通信的高级形式,支持不同进程间的通信,这两个进程可以在同一台机器,也可以在不同机器。socket 是网络和互联网编程的基础。
在 Linux,可以用 ls/stat 命令 和 stat() 系统调用确定文件类型。 $ ls -li 12587634 drwxr-xr-x 26 root root 4096 Mar 16 07:49 1.opensource27396428 lrwxrwxrwx 1 root root 12 Nov 17 2017 Link to ssd_dvd -> /mnt/ssd_dvd12582945 -rw-r--r-- 1 root root 665 Jul 10 18:47 minicom.log$ stat minicom.log File: 'minicom.log' Size: 665 Blocks: 8 IO Block: 4096 regular fileDevice: 822h/2082d Inode: 12582945 Links: 1Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)Access: 2020-01-09 09:44:07.101177618 +0800Modify: 2020-07-10 18:47:20.073532673 +0800Change: 2020-07-10 18:47:20.073532673 +0800
3. 文件描述符在 Linux 中,文件必须先打开才能访问。对于内核而言,所有打开的文件都通过文件描述符 ( file descriptor,简称fd ) 引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读、写一个文件时,使用 open() 或 creat() 返回的文件描述符标识该文件,将其作为参数传送给 read() 或 write()。 - Linux 系统编程的大部分工作都会涉及打开、操纵、关闭以及其他文件描述符操作;
- Linux 系统的 Shell 把文件描述符 0 与进程的标准输入 stdin 关联,文件描述符 1 与标准输出 stdout 关联,文件描述符 2 与标准错误 stderr 关联。这是各种 Shell 以及很多应用程序使用的惯例,与 Linux 内核无关。如果不遵循这种惯例,很多 Linux 系统应用程序就不能正常工作;
- 用户可以重定向文件描述符,甚至可以通过管道把一个程序的输出作为另一个程序的输入。Shell 就是通过这种方式实现重定向和管道的。
- 在 POSIX 标准中,幻数 0、1、2 虽然已被标准化,但应当把它们替换成符号常量 STDIN_FILENO、STDOUT_FILENO 和 STDERR_FILENO 以提高可读性;
- 文件描述符的范围是 0 ~ OPEN_MAX-1;
- 文件描述符并非局限于访问普通文件。实际上,文件描述符也可以访问设备文件、管道、FIFO、Socket等。遵循一切皆文件的理念,几乎任何能够读写的东西都可以通过文件描述符来访问。
4. 通用文件模型:简介Linux 通用文件模型最为显著的特性之一就是 I/O 通用性。也就是说,同一套系统调用 open()、read()、write()、close() 等所执行的 I/O 操作,可施之于所有文件类型,包括设备文件在内。应用程序发起的I/O请求,内核会将其转化为相应的文件系统操作,或者设备驱动程序操作,以此来执行针对目标文件或设备的I/O操作。因此,采用这些系统调用的程序能够处理任何类型的文件。 演示 demo (copy.c): int main(int argc, char *argv[]){ int inputFd, outputFd, openFlags; mode_t filePerms; ssize_t numRead; char buf[BUF_SIZE]; if (argc != 3 || strcmp(argv[1], "--help") == 0) usageErr("%s old-file new-file\n", argv[0]); /* Open input and output files */ inputFd = open(argv[1], O_RDONLY); if (inputFd == -1) errExit("opening file %s", argv[1]); openFlags = O_CREAT | O_WRONLY | O_TRUNC; filePerms = S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH; /* rw-rw-rw- */ outputFd = open(argv[2], openFlags, filePerms); if (outputFd == -1) errExit("opening file %s", argv[2]); /* Transfer data until we encounter end of input or an error */ while ((numRead = read(inputFd, buf, BUF_SIZE)) > 0) if (write(outputFd, buf, numRead) != numRead) fatal("write() returned error or partial write occurred"); if (numRead == -1) errExit("read"); if (close(inputFd) == -1) errExit("close input"); if (close(outputFd) == -1) errExit("close output"); exit(EXIT_SUCCESS);}
运行效果: $ ./copy test test.old$ ./copy test /dev/tty$ ./copy /dev/tty abc.txt
相关要点: - 要实现通用 I/O,就必须确保每一种文件系统和每一种文件类型(包括设备文件)都实现了相同的 I/O 系统调用集。由于文件系统或设备文件所特有的操作细节在内核中处理,在编程时通常可以忽略设备专有的因素。一旦应用程序需要访问文件系统或设备的专有功能时,可以选择瑞士军刀般的 ioctl() 系统调用,该调用为通用 I/O 模型之外的专有特性提供了访问接口。
- 提到通用 I/O,就必须提起虚拟文件系统 (VFS)。为支持各种本机文件系统,且在同时允许访问其他操作系统的文件,Linux 内核在用户进程和文件系统实现之间引入了一个抽象层 VFS。虚拟文件系统基于文件通用模型(common file model,简称CFM)实现这种抽象,它是 Linux 上所有文件系统的基础。
- 一方面,VFS 提供了一种操作文件、目录及其他对象的统一方法。另一方面,它与各种具体的文件系统的实现达成妥协。我们可以认为,是虚拟文件系统 (VFS) 和通用文件模型 (CFM) 的共同作用为 Linux 提供了访问不同文件系统以及不同类型的文件的 统一API (open()、read()、write()、close())。在本文中,我们将重点放在文件上,忽略文件系统相关的东西。
- 在 VFS 中,并非所有文件系统都支持同样的功能,有些操作对普通文件是不可缺少的,对某些对象则完全没有意义。即并非每一种文件系统都支持 VFS 中的所有抽象。
- Linux VFS 的实现: 参考 ext2 文件系统,提供一种结构模型,该文件系统模型包含了一个强大文件系统所应具备的所有组件。但该模型是虚拟的,它适应于各种真实的文件系统。所有实现都必须提供可以适应 VFS 定义的结构体的 routines,因此可以充当两个视图之间的过渡。
- 在 VFS 中,每个文件都关联到一个 inode,我们可以 以 inode 和 inode->file_operations 作为学习通用文件模型和虚拟文件系统的切入点。
struct inode { umode_t i_mode; ... const struct file_operations *i_fop; ...}struct file_operations { struct module *owner; loff_t (*llseek) (struct file *, loff_t, int); ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); ... long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); long (*compat_ioctl) (struct file *, unsigned int, unsigned long); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id);...} __randomize_layout;
5. 通用文件模型:文件描述符和打开文件的关系5.1 相关的内核数据结构内核使用 3 种数据结构来表示一个被打开的文件:- 进程级的文件描述符表 ( file descriptor table )。
- 系统级的打开文件表 ( open file table ) 。
- 文件系统的 i-node 表 ( i-node table )。
1) 进程级的文件描述符表 ( file descriptor table )每个进程在进程表 (process table) 中都有一个记录项 (process table entry),即 struct task_struct,内核用它来描述一个进程。在 struct task_struct 中包含了一张打开文件描述符表 (open file descriptors table),由 struct files_struct 里的 struct fdtable 来表示 (Linux-4.14): struct task_struct { ... /* Filesystem information: */ struct fs_struct *fs; /* Open file information: */ struct files_struct *files; -> struct fdtable *fdt; ...}
每个文件描述符包含: - 1> 文件描述符标志 ( file descriptor flags,目前只有一个:close_on_exec,暂不关心 );
- 2> 指向一个打开文件表项 ( open file table entry) 的指针。
struct fdtable { ... struct file **fd; /* current fd array */ unsigned long *close_on_exec; ...};

2) 系统级的打开文件表 ( open file table )
内核为所有打开文件维持一张打开文件表。每个打开文件表项包含: - 1> 文件状态标志 ( file status flags,即 open() 的 flags 参数);
- 2> 当前文件偏移量 ( current file offset );
- 3> 指向该文件 inode 表项的指针 (在某些 UNIX 系统中是 vnode pointer,在 Linux 中是 inode pointer)。
inode 结构体和 vnode 结构体名称虽然不同,但是 2 者其实是同一个概念,它们都用于描述存储在硬盘中的文件系统的 inode 数据。注意区别内存里的 inode 结构体对象和硬盘中的 inode 数据。 3) 文件系统的 i-node 表 ( i-node table )每个打开文件都有一个 inode 对象。inode 对象包含了: - 文件类型和对此文件进行各种操作函数的指针。
- 对于大多数文件,inode 对象还包含了指向该文件系统 inode 数据的指针。
struct inode { ... /* Stat data, not accessed from path walking */ unsigned long i_ino; ... /* former ->i_op->default_file_ops */ const struct file_operations *i_fop; }
这些信息是在打开文件时从硬盘上读入内存的,所以,文件的所有相关信息都是随时可用的。即 inode 对象包含了文件的所有者、文件长度、指向文件实际数据块在磁盘上所在位置的指针等。 上述三张表的完整关系如下:

5.2 列举几种打开文件的情景1) 两个独立进程各自打开同一个文件两个独立进程各自打开了同一文件,则有如下关系:
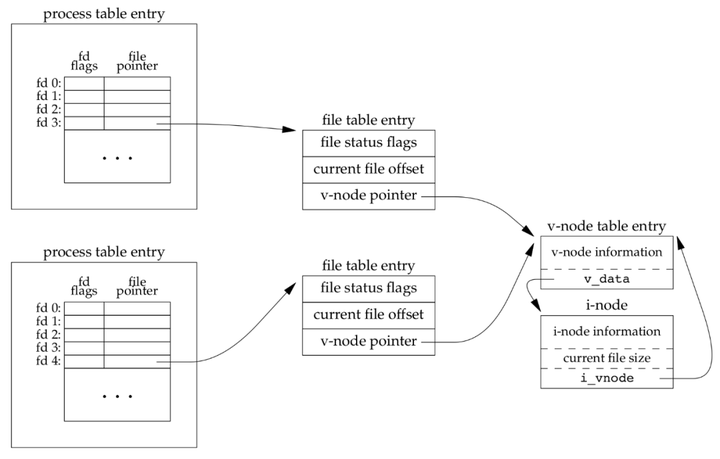
第一个进程在文件描述符 3 上打开该文件,而另一个进程在文件描述符 4 上打开该文件。打开该文件的每个进程都获得各自的一个打开文件表项,但对一个给定的文件只有一个 inode 节点表项。 之所以每个进程都获得自己的打开文件表项,是因为这可以使每个进程都有它自己的对该文件的当前偏移量。 2) dup(1) 复制文件描述符dup() 用来复制一个现有的文件描述符。 $ man 2 dup #include <unistd.h> int dup(int oldfd);
dup(1)后的内核数据结构:
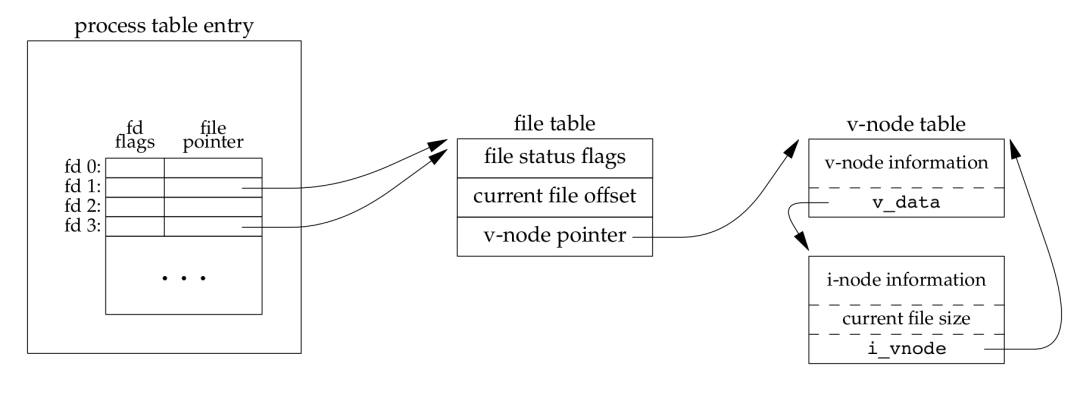
dup() 返回的新文件描述符与参数 oldfd 共享同一个打开文件表项。 3) fork 之后父进程和子进程之间对打开文件的共享
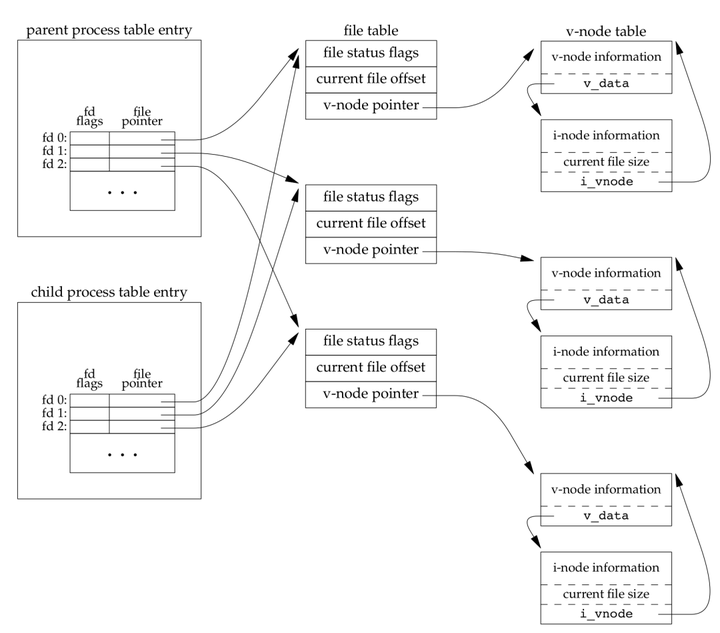
假定所用的描述符是在fork之前打开的,如果父进程和子进程写同一描述符指向的文件,但又没有任何形式的同步,如使父进程等待子进程,那么它们的输出就会相互混合。 有相同爱好的可以进来一起讨论哦:企鹅群号:1046795523
| 

 /1
/1 


 |手机版|OpenEdv-开源电子网
( 粤ICP备12000418号-1 )
|手机版|OpenEdv-开源电子网
( 粤ICP备12000418号-1 )









 发表于 2020-8-12 16:33:05
发表于 2020-8-12 16:33:05
