|
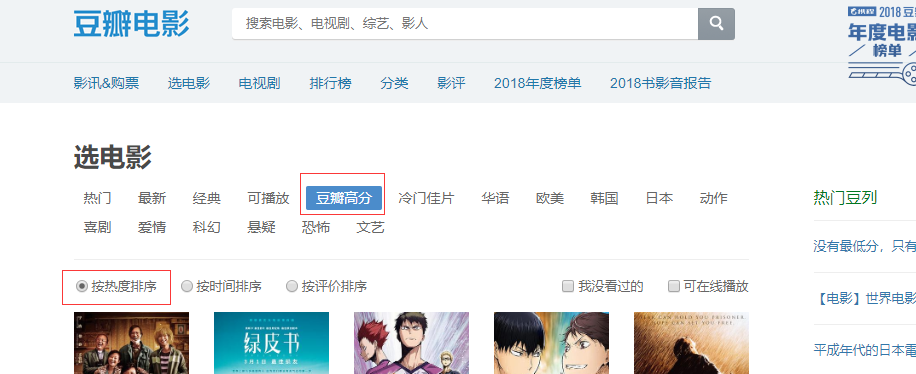
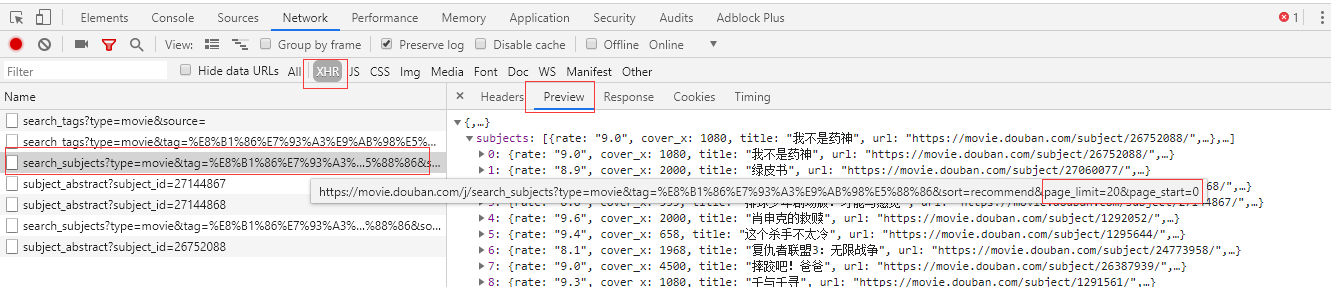
主要对豆瓣高分电影,按热度排序进行电影信息的爬取 分析 按F12打开开发者工具,点击XHR标签,因为他是通过ajax加载获取更多的电影信息的。返回的信息是json格式的数据,包含了每部电影详情的链接信息,先获取这些信息讨论764261140
页码每次最后的 page_start参数 加20可以换到下一页
下面是详细代码 [url=] [/url] [/url]
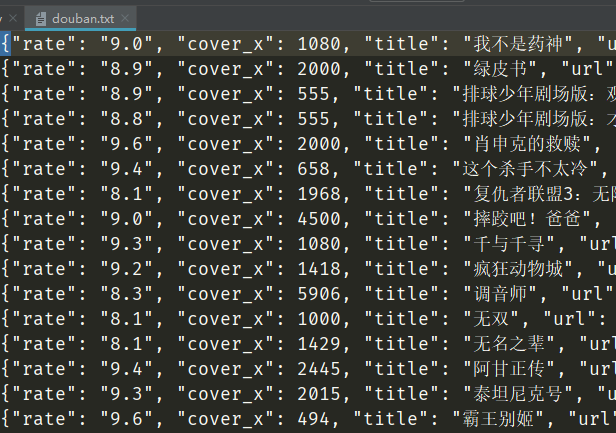
import re, requestsimport jsonclass DoubanSpider: def __init__(self): self.url_temp = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=recommend&page_limit=20&page_start={}" self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"} def parse_url(self, url): # 发送请求,获取响应 print(url) response = requests.get(url, self.headers) return response.content.decode() def get_content_list(self, json_str): # 提取数据 dict_ret = json.loads(json_str) print(dict_ret) content_list = dict_ret["subjects"] # 所有电影数据 return content_list def save_content_list(self, content_list): # 保存 with open("douban.txt", 'a', encoding="utf-8") as f: for content in content_list: f.write(json.dumps(content, ensure_ascii=False)) f.write("\n") # 写入换行符 print("保存成功") def run(self): # 实现主要逻辑 num = 0 while True: # 1、构造start_url url = self.url_temp.format(num) # 2、发送请求,获取响应 json_str = self.parse_url(url) # 3、提取数据 content_list = self.get_content_list(json_str) # 4、保存 self.save_content_list(content_list) # 5、判断是否有下一页 if len(content_list) < 20: break # 6、构造下一个url地址 num += 20if __name__ == '__main__': douban = DoubanSpider() douban.run()[url=][/url]
| 

 /1
/1 


 |手机版|OpenEdv-开源电子网
( 粤ICP备12000418号-1 )
|手机版|OpenEdv-开源电子网
( 粤ICP备12000418号-1 )









 发表于 2020-8-12 10:07:09
发表于 2020-8-12 10:07:09